
The Agent Authority Broker for AI Systems
Crittora brokers authority between AI agents and the tools, APIs, workflows, and connected accounts they can use. Every action is checked before execution and recorded with proof.
CRITTORA AGENT AUTHORITY BROKER
THE MISSING CONTROL BETWEEN AI AGENTS AND REAL SYSTEMS
Most agent stacks leave agents with ambient authority once tools, credentials, and vendor accounts are connected. Crittora Agent Authority Broker controls exactly what an agent is allowed to do at the moment of action, then records the AI-facing user, downstream identity, operation, policy decision, and proof.

Scope Permissions
Grant only the permissions required for a specific action.

Control Tool Access
Limit which tools an agent can touch at runtime.

Audit Every Action
Record what happened, who requested it, and when.
Why Autonomy Stalls
Control Breaks At Execution
Agent systems fail when tool access is implicit and runtime authority is not enforced at the moment of action.

"Most agent security claims sound strong until you ask a simple question: what actually controls the action when the agent touches a real tool? If the answer is vague, the system is not ready for production."
-
Security Leader, Enterprise AI
How Crittora Brokers Agent Authority
Crittora Agent Authority Broker brings Crittora's authority model to MCP-compatible stacks in minutes, while preserving the same policy, enforcement, and proof model.
FAST INSTALL. HARD STOP AT EXECUTION.
Deploy the MCP-native Permission Gate in minutes, then require every state-changing tool call to pass a mandatory runtime checkpoint before anything can commit.

EXACT AUTHORITY FOR EACH STEP
Agents never hold broad or long-lived access. Authority is granted just in time for a specific action, tool, and execution step.
INTEGRITY AT THE TOOL BOUNDARY
Requests, responses, and execution context stay protected as they move across orchestrators, MCP tools, and downstream services so approved actions stay intact.

PROOF AFTER EVERY ACTION
Each approved step emits a signed, portable record tying agent identity, user context, connected account, policy, and request data together for audit, forensics, and review.
Stop unauthorized agent actions.
Agent Permission Protocol
The Protocol Behind Crittora Agent Authority Broker
APP is the policy and permission protocol behind Crittora Agent Authority Broker. It binds each agent action to signed, time-bound scope before tools are exposed.
It gives Crittora Agent Authority Broker its authority model: scoped permissions, runtime enforcement, and signed proof for every action.
Agent Authority Readiness Evaluation
Evaluate Your Agent
Before It Touches Production
We review how your agent stack handles tool access, authority boundaries, and runtime proof so you can see exactly where control breaks and how to close the gap.
What We Test
State-changing tool calls (APIs, admin actions, automation triggers)
Authority boundaries (scope, expiry, audience binding)
Failure modes (replay, tampering, confused deputy, over-broad tokens)
What You Get
Signed Proof-of-Action receipts for allow/deny
A policy map of tool access by agent/workflow
A short risk summary (blast radius + recommended constraints)
AI agents are moving closer to real decisions and real tool execution. The risk surface is growing with them.
40%+
Agentic AI projects Gartner predicts will be canceled by 2027 without clearer value and risk controls
80%
Companies reporting AI agents have taken unintended actions, including unauthorized access or data sharing
84%
Security professionals reporting an API security incident in the past 12 months
1 in 8
Reported AI breaches HiddenLayer links to autonomous agentic systems
Sources: Gartner, SailPoint, HiddenLayer, Akamai · Updated May 18, 2026

FOR DEVELOPERS & AGENT ARCHITECTS
DEPLOY AGENT AUTHORITY BROKERAGE IN MINUTES
Crittora's MCP-native Permission Gate is a direct way to add runtime authority brokerage to any MCP-compatible agent stack.
Use it to control what agents can do, which tools and connected accounts they can touch, and what proof is recorded for every allow or deny decision.
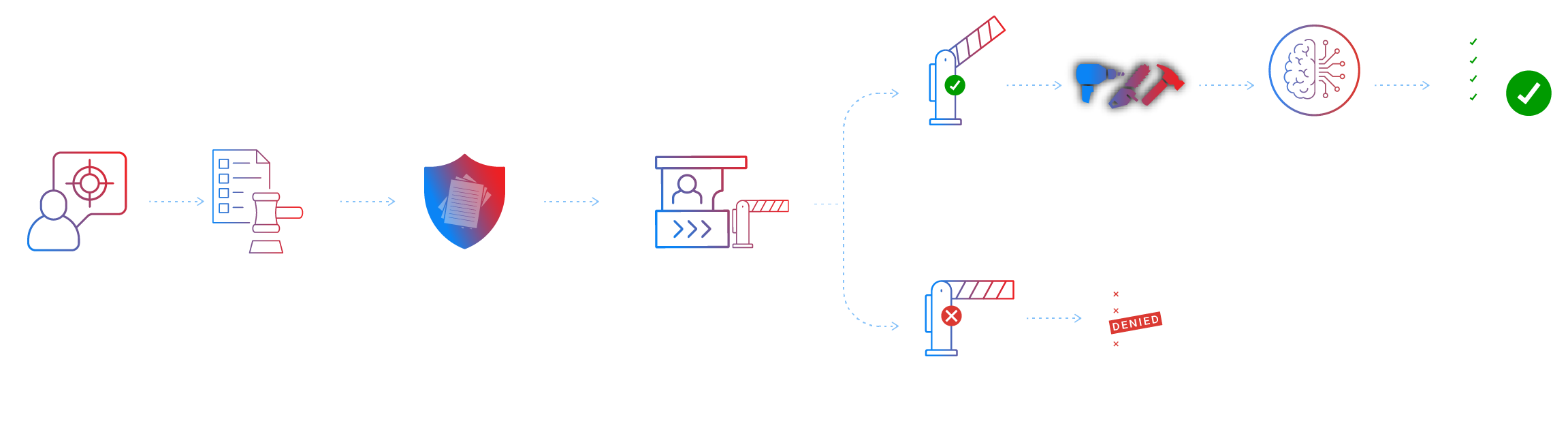
Deploy Crittora in front of state-changing APIs and automations. Before a request reaches a system of record, Crittora verifies integrity and evaluates the action against explicit scope and expiry. Out-of-scope, expired, replayed, or tampered requests fail closed.
Wrap tool calls inside LangGraph, LangChain, or custom runtimes so the agent only receives a restricted tool surface for each step. Tools are exposed only when authorized, and the wrapper emits receipts inline with workflow execution.
Add the Permission Gate to any MCP-compatible runtime to enforce scoped tool access, fail-closed authorization, connected-account governance, and signed audit receipts without model lock-in. This is the fastest path to bringing Crittora's authority model into a running agent stack.
FOR AGENT BUILDERS
Questions Teams Should Ask Before Agents Reach Production
Clear answers on scoped authority, approvals, MCP integrations, and audit proof.
Ambient authority means access exists by default instead of being granted for a specific action. In agent systems, this happens when a model can reach mounted tools, broad OAuth tokens, API keys, or privileged integrations without a fresh execution-time authorization decision. Crittora eliminates ambient authority by exposing only the capabilities allowed by a verified, time-bounded policy.
Execution-time authorization is the control point between agent intent and real system change. Instead of approving broad access at login, planning, or setup, the execution layer checks the action, tool, scope, audience, expiry, and policy proof immediately before the tool call or API operation can commit. If authorization is missing, expired, ambiguous, or out of scope, execution fails closed.
Authentication and identity are necessary, but they do not limit action by themselves. A valid agent identity or OAuth token can still carry broad authority across many tools. AI agent security needs execution-time authorization so every tool call is scoped to the current task, time window, and permitted capability. Identity answers who. Execution-time authorization answers what can happen now.
Crittora Agent Authority Broker sits between agents and tools, APIs, or systems of record. Before an agent can use a sensitive capability, Crittora verifies the policy, validates scope and expiry, blocks unauthorized calls, and emits proof of what was allowed or denied. That makes Crittora the execution-time authorization layer for AI agents.
Request the Crittora Agent Authority Broker demo.
Walk through how Crittora checks agent identity, permission boundaries, connected account context, and operation-level authority before execution.
Request Demo